March 2026 will be remembered as the month the AI industry pivoted from „build bigger models” to „make them useful at scale.” While NVIDIA announced trillion-dollar infrastructure plans and the Pentagon labeled Anthropic a supply-chain risk, the real story was buried in the numbers: nine text models shipped, seven were open-weight, and the entire leaderboard moved at once. 
GPT-5.4 (OpenAI)
https://openai.com/index/introducing-gpt-5-4

OpenAI released GPT-5.4 on March 5, scoring 57.17 on the Artificial Analysis Intelligence Index—virtually tied with Google’s Gemini 3.1 Pro Preview at 57.18, a gap of just 0.01 points. The model comes in three versions: Standard, Thinking, and Pro, with native computer-use capabilities. GPT-5.4 is 33% less likely to make errors than GPT-5.2 and achieves 83% match or exceed industry professionals on knowledge work tasks across 44 occupations. The Pro version targets enterprise scale, priced at $5.63 per million tokens. Yet the story barely registered, overshadowed by infrastructure announcements and geopolitical drama.
Grok 4.20 (xAI)
https://docs.x.ai/developers/models

Released March 12, Grok 4.20 from xAI introduced a revolutionary 4-agent system where Grok serves as captain, Harper handles research, Benjamin manages math and code, and Lucas drives creative work. The model boasts an industry-leading 78% non-hallucination rate and a 256K token context window (potentially 2M in agent modes), beating competitors on factual accuracy benchmarks. Intelligence Index: 48.48.
Gemini 3.1 Flash-Lite (Google)
https://deepmind.google/models/model-cards/gemini-3-1-flash-lite

Google’s Gemini 3.1 Flash-Lite launched March 3 as a strong efficiency-tier addition for production APIs, focusing on multimodal, reasoning, and agentic properties through a unified approach from Google DeepMind. Priced at $0.25 per 1M input tokens and $1.50 per 1M output tokens, it represents a significant cost reduction for high-volume workloads. Intelligence Index: 34.
MiniMax-M2.7 (MiniMax)
https://www.minimax.io/models/text/m27

Released March 18, MiniMax-M2.7 scored 49.62 on the Intelligence Index at just $0.53 per million tokens—the best price-to-quality ratio in its tier. This is the third iteration of MiniMax’s M2 line, with each version shipping with tighter factual accuracy and lower cost. M2.7 demonstrates significant improvement in complex editing capabilities and autonomous self-improvement through recursive self-optimization.
MiMo-V2-Pro (Xiaomi)
https://mimo.xiaomi.com/mimo-v2-pro

Also released March 18, Xiaomi’s MiMo-V2-Pro achieved 49 on the Intelligence Index with an Elo rating of 1426 on agentic tasks, making it competitive for tool-calling and multi-step workflows. The model is designed as the brain of agentic systems for real-world workloads. Both MiniMax-M2.7 and MiMo-V2-Pro are open-weight, both score near 49-50, and both were released the same day—whether coincidence or competitive signaling, the result was clear: the tier handling most production workloads got two strong new entrants in a single afternoon. The month also saw GLM 5.1 from Zhipu and the revelation that Cursor’s new Composer 2 was built on Kimi K2.5, highlighting the increasing cross-border collaboration and technology sharing in the open-source AI ecosystem.
NVIDIA Nemotron 3 Series
https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16

NVIDIA’s Nemotron 3 Super (March 11) is a 120B MoE with 12B active parameters (10% active ratio), designed for agentic reasoning and complex instruction-following tasks. Full parameter checkpoints are available on Hugging Face and through NVIDIA NIM. The model is suitable for long-context reasoning and represents NVIDIA’s push into open, production-ready enterprise models.
Mistral Small 4 (Mistral AI)
https://huggingface.co/mistralai/Mistral-Small-4-119B-2603

Released March 20, Mistral Small 4 delivered an Apache 2.0 licensed MoE model with 119B total parameters and 6.5B active (5.5% active ratio), with a 256K context window. The model unifies instruct, reasoning, and coding capabilities in a single, powerful hybrid model, continuing Mistral’s push into efficient, self-hostable alternatives.
Cursor Composer 2

Cursor Composer 2 makes specialized code models the empirically correct default, targeting pure coding tasks with unprecedented accuracy. The model is available in Standard ($0.50/M input, $2.50/M output) and Fast ($1.50/M input, $7.50/M output) variants. Notably, Cursor confirmed that Composer 2 was built on top of Moonshot AI’s Kimi K2.5 technology, marking a significant collaboration between the coding IDE and the Chinese AI lab.
GLM 5.1 (Zhipu)
https://huggingface.co/THUDM/glm-5-1

Zhipu released GLM 5.1 in March, continuing its aggressive release schedule. The model represents an incremental update to the GLM line with improvements in reasoning, coding, and multimodal capabilities. GLM 5.1 maintains the open-weight approach that has made the GLM series popular in the open-source community.
Google’s TurboQuant: The Quantization Breakthrough
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression

On March 24, Google Research unveiled TurboQuant, a set of advanced, theoretically grounded quantization algorithms that caused significant excitement across the AI community. TurboQuant addresses the critical challenge of memory overhead in vector quantization, which had previously limited compression gains.
The breakthrough works through two key steps: first, it randomly rotates data vectors to simplify geometry, then applies high-quality quantization to each part individually. Second, it uses a residual 1-bit stage with the Quantized Johnson-Lindenstrauss (QJL) algorithm to eliminate bias and errors. The result is remarkable: TurboQuant can quantize key-value caches to just 3 bits without any training or fine-tuning, with zero accuracy loss. On H100 GPU accelerators, 4-bit TurboQuant achieves up to 8x performance increase over 32-bit unquantized keys.
This breakthrough has profound implications for all compression-reliant use cases, especially in search and AI inference. By enabling extreme compression without sacrificing model performance, TurboQuant addresses one of the most critical bottlenecks in scaling AI systems: memory bandwidth and capacity constraints.
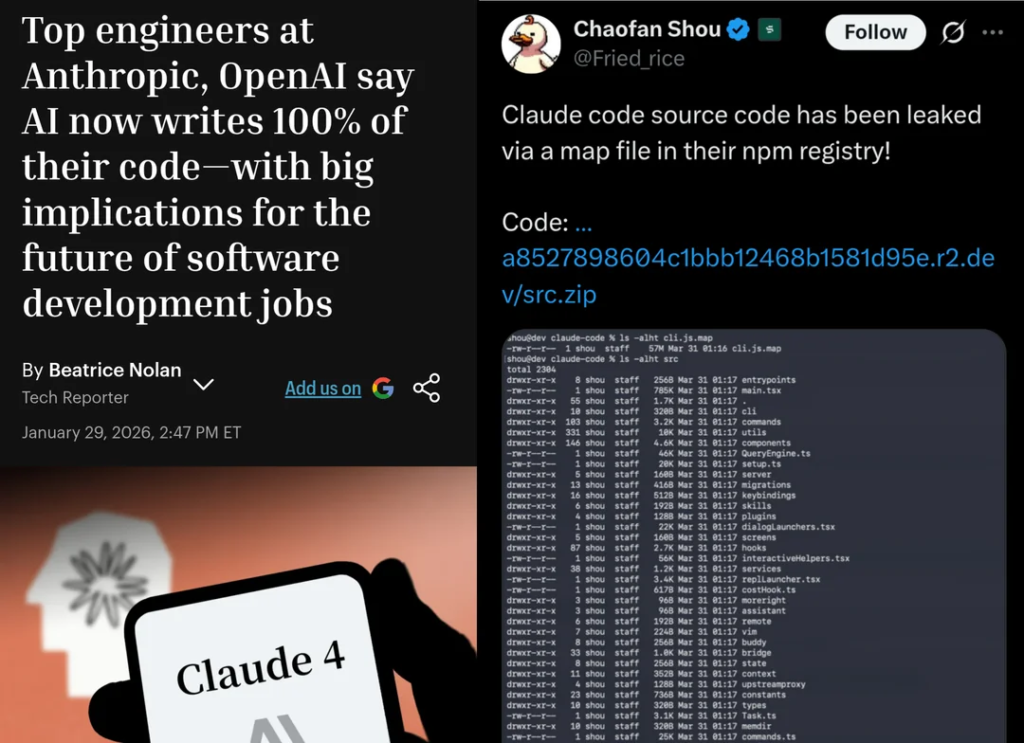
The Great Claude Code Leak

On March 31, Anthropic accidentally published the entire source code for Claude Code in what might be the most significant intellectual property leak in AI history. A 59.8 MB JavaScript source map file intended for internal debugging was inadvertently included in a public npm package. Within hours, the ~512,000-line TypeScript codebase was mirrored across GitHub.
The leak revealed Anthropic’s sophisticated „Self-Healing Memory” architecture, which solves context entropy by using a lightweight index of pointers rather than storing all data in context. It also exposed „KAIROS,” an autonomous daemon mode that performs background memory consolidation while the user is idle, and an „Undercover Mode” used for stealth contributions to public repositories. For competitors, this leak provided a $2.5 billion blueprint for building high-agency, reliable AI agents.
Critical Supply Chain Vulnerabilities: LiteLLM and Axios
https://snyk.io/articles/poisoned-security-scanner-backdooring-litellm

March 2026 exposed critical vulnerabilities in AI and web infrastructure dependencies. On March 24, threat actor TeamPCP compromised the widely-used LiteLLM Python package (versions 1.82.7 and 1.82.8 ) after stealing PyPI credentials through a prior compromise of Trivy, an open-source security scanner used in LiteLLM’s CI/CD pipeline. The malicious versions contained a sophisticated three-stage backdoor that collected system data, cloud credentials (AWS, GCP, Azure), SSH keys, Kubernetes secrets, and cryptocurrency wallets before exfiltrating everything encrypted to a command-and-control server. The attack cascaded through developer tooling, affecting LiteLLM’s 3.4 million daily downloads. The packages were available for approximately three hours before PyPI quarantined them.
Just days later, on March 31, attackers compromised the npm account of axios, the most popular JavaScript HTTP client library with over 100 million weekly downloads. The attacker published two malicious versions: axios@1.14.1 and axios@0.30.4, which injected a hidden dependency called plain-crypto-js@4.2.1. This fake package contained a post-install script that deployed a cross-platform remote access trojan (RAT) dropper targeting macOS, Windows, and Linux. The dropper contacted a live command-and-control server, delivered platform-specific second-stage payloads, then deleted itself and replaced its package.json with a clean version to evade forensic detection. The malicious versions were live for approximately 2-3 hours before npm unpublished them. The attack was characterized by surgical precision: the malicious dependency was staged 18 hours in advance, three OS-specific payloads were pre-built, and the malware executed within two seconds of npm install, calling home to the attacker’s server before npm had even finished resolving dependencies.
These incidents highlighted how AI and web infrastructure, built on layers of open-source dependencies, remains vulnerable to supply chain attacks that can compromise entire systems at scale.
NVIDIA GTC 2026: Vera Rubin and the $1 Trillion Bet
https://blogs.nvidia.com/blog/gtc-2026-news

At NVIDIA’s annual GTC conference (March 16-19), CEO Jensen Huang unveiled Vera Rubin, the company’s next-generation computing platform designed specifically for agentic AI. The full-stack platform comprises seven chips, five rack-scale systems, and one supercomputer. Huang claimed ~10x training cost reduction for trillion-parameter models and announced $1 trillion in infrastructure orders in the pipeline through 2027.
The platform includes the new NVIDIA Vera CPU and BlueField-4 STX storage architecture. Huang also teased the architecture beyond Rubin, codenamed Feynman, which will feature a new CPU named Rosa (after Rosalind Franklin) and the LP40 LPU. This next generation will pair with NVIDIA BlueField-5 and CX10, connected through NVIDIA Kyber for both copper and co-packaged optics scale-up, and NVIDIA Spectrum-class optical scale-out.
Huang stated he expects at least $1 trillion in revenue from 2025 through 2027, noting that computing demand has increased by 1 million times over the last few years. The NVIDIA Vera Rubin DSX AI Factory reference design and NVIDIA Omniverse DSX Blueprint allow companies to simulate AI factories in software before building them physically. In an unexpected move, Huang announced that NVIDIA is going to space, with future systems like NVIDIA Space-1 Vera Rubin designed to bring AI data centers into orbit.
Intel Arc Pro B70: 32GB VRAM for $949

Intel made a major play for the local AI inference market with the Arc Pro B70 and B65 GPUs, based on the „Big Battlemage” architecture. Launching on March 25, the B70 features 32GB of ECC GDDR6 memory on a 256-bit bus, delivering 608 GB/s of bandwidth—crucial specs for running large language models locally.
The B70 features 32 Xe Cores running at 2800 MHz for 22.9 TFLOPS of FP32 compute performance, with a power envelope ranging from 160W to 290W. Priced at just $949, the B70 significantly undercuts NVIDIA’s $1,800 RTX Pro 4000 24GB and AMD’s $1,299 Radeon AI Pro R9700. Intel highlights multi-GPU support for scaling LLM serving across multiple Arc Pro cards.
The Arc Pro B65 keeps the 32GB of memory and 608 GB/s bandwidth but drops to 20 Xe Cores, making it appealing for users needing memory capacity without maximum compute horsepower. While Intel’s software ecosystem (CUDA compatibility) remains a hurdle, the sheer value proposition of 32GB VRAM for under $1,000 makes this highly attractive for local LLM enthusiasts and researchers.
Memes of the month from r/localllama: